
Python의 Pandas 라이브러리 사용시
pandas는 DataFrame이라는 클래스를 사용하여, 데이터를 자유롭게 다룰 수 있는 훌륭한 라이브러리 이다.
그런데 Bigdata를 다룰때, 일일히 pd.read_csv()를 사용하여, 데이터를 부른다면,
시간이 엄청나게 소모될 것이다.
굳이 원본 데이터를 읽을 필요 없이, 데이터만 엑셀 데이터에 붙여넣어 준다면, 시간을 대폭 감소할 수 있을 것이다.
원하는 동작
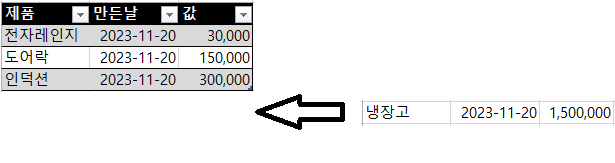
Python 코드
import pandas as pd
import os
# 샘플 데이터 생성
new_data = {'제품': ['냉장고'], '만든날': [2023-11-20],'값':[1500000]}
new_df = pd.DataFrame(new_data)
#일단 원본데이터가 있는지 검증하고, 없으면 to_csv로 그냥 저장하고
#이미 원본데이터가 있다면, 기존데이터에 Append(누적)하는 코드
if not os.path.exists('./경로/original.csv'):
new_df.to_csv('./경로/original.csv', index=False, mode='w', encoding='utf-8-sig')
else:
new_df.to_csv('./경로/original.csv', index=False, mode='a', encoding='utf-8-sig', header=False)즉, mode에 따라서 "덮어쓰기(w)"와 "누적(a)"로 구분된다.
encoding의 경우 한글이라면 utf-8-sig를 사용하는 것이 좋다.
to_csv로 저장한 파일의 한글이 깨질때 해결방법 ↓
[Python / 파이썬]pandas to_csv로 저장한 csv파일의 한글이 깨질때
df.to_csv 한글 깨짐 import pandas as pd df.to_csv('./경로/파일명') 위 코드로 저장한 .csv 파일의 한글이 깨지는 문제가 발생, encoding="utf-8"를 해도 안되는 경우가 있습니다. import pandas as pd df.to_csv('./경로/
mrnoobiest.tistory.com
끝.
728x90
반응형



