태블로 서버 데이터(Hyper) ---> Dataframe(Python)
태블로 서버에 게시된 데이터 원본을 Python으로 다운로드는 하는것은 쉽지만, 문제는 이렇게 다운받은 데이터 원본은 .tdsx의 확장자를 가진다는게 문제다.
물론 해당 파일의 확장자를 .zip으로 변경하여 압축을 풀고, 압축해제한 폴더내에 Data가 들어 있지만, 이게 csv일때도 있고 .hyper일때도 있다.
이번엔 Python의 TSC(Tableau Server Client)라이브러리를 사용하여
"Tableau Server의 데이터 원본 다운로드" >>> "csv가 아닌 hyper일경우 dataframe으로 변경" >>> "수정 후 다시 업로드 하는 일련의 과정"을 알아보자.

TSC(Tableau Server Client) 라이브러리
TSC 설명서에는 datasources.download를 실행시 .hyper로 다운받을 수 있다고 나오는데
github에 기재된 코드를 아무리 봐도 hyper형식으로 다운받을 수 있는 옵션이 보이지 않는다
ALLOWED_FILE_EXTENSIONS = ["tds", "tdsx", "tde", "hyper", "parquet"] 에는 hyper가 떡하니 있지만 어디에도 다운받을때 데이터 형식을 결정하는 옵션이 보이지 않는다.
혹시 아는 사람이 있으면 댓글로 공유바랍니다.
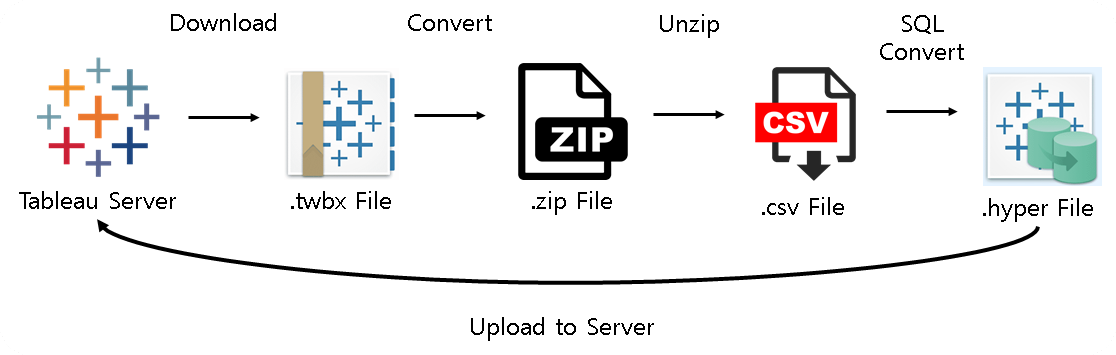
진행 과정
진행 과정은 아래와 같다.
1) 다운받고자 하는 데이터 원본 or 대시보드 다운로드
2) 다운받은 .tdsx or .twbx 를 zip으로 변경 후 압축 해제
3) 압축 해제된 폴더내 Data를 가져오기
4) 가져온 데이터가 .hyper일 경우 .csv로 변환하기
5) 수정이 됬다는 가정하에 기존의 데이터 원본 덮어쓰기
위 일련의 진행 과정을 Python으로 구현해보았다.
Tableau Server의 데이터 가져오기
1) 다운받고자 하는 데이터 원본 or 대시보드 다운로드
1-1) 다운받고자 하는 데이터 원본 또는 TWBX의 ID 찾기
1-2) 1-1)에서 찾은 ID로 다운로드하기
import tableauserverclient as TSC
import numpy as np
import pandas as pd
import zipfile
import os
import sys
#서버 접속
tableau_auth = TSC.TableauAuth('서버_ID', '서버_ID_PW','')
server = TSC.Server('Tableau Server URL', use_server_version=True)
count=0
#TSC로 서버정보를 읽을때 제한을 100에서 1000으로 늘려주기
req_option = TSC.RequestOptions(pagesize=1000)
#데이터 원본명으로 ID찾기
with server.auth.sign_in(tableau_auth):
all_datasources = list(TSC.Pager(server.datasources, req_option))
datasource='Tableau_Datasource_File_Name'
datasource_id = [i.id for i in all_datasources if i.name==datasource]
datasource_name = [i.name for i in all_datasources if i.name==datasource]
print(datasource_id)
print(datasource_name)
#이어서 이렇게 알아낸 ID를 사용하여 데이터를 다운로드한다.
server.datasources.download(datasource_id[0], filepath='/File_Path_Location/')
from pathlib import Path
p = Path('/File_Path_Location/Tableau_Datasource_File_Name.tdsx')
p.rename(p.with_suffix('.zip'))
Filename = 'Tableau_Datasource_File_Name.hyper'
#Zip을 압축해제하고 해제한 곳에서 데이터(.hyper)를 가져오기
with zipfile.ZipFile('/File_Path_Location/Tableau_Datasource_File_Name.zip') as zip:
for zip_info in zip.infolist():
if zip_info.filename[-1] == '/':
continue
if zip_info.filename.endswith('.hyper'):
zip_info.filename = Filename
zip.extract(zip_info, '/File_Path_Location/')
#정말 단순 무식하게 한것인데, 다운받은 tdsx파일을 zip으로 형변환을 하고
#zip을 압축 해제하면 생성된 Datasource폴더안에 있는 .hyper데이터 원본을 가져오는것이다.
#위에서 다운로드 받은 hyper을 쿼리문을 사용하여 각 row(행)으로 쪼개서 Dataframe에 저장한다.
from tableauhyperapi import HyperProcess, Connection, TableDefinition, SqlType, Telemetry, Inserter, CreateMode, TableName
from tableauhyperapi import escape_string_literal
#아래 table_name은 hyper파일을 열어 확인후 변경하세요.
table_name=TableName('Extract','Extract')
result_list=[]
with HyperProcess(telemetry=Telemetry.SEND_USAGE_DATA_TO_TABLEAU ) as hyper:
# Connect to an existing .hyper file (CreateMode.NONE)
with Connection(endpoint=hyper.endpoint, database='/File_Path_Location/Tableau_Datasource_File_Name.hyper') as connection:
table_names = connection.catalog.get_table_definition(name=table_name)
with connection.execute_query(query=f"SELECT * FROM {TableName(table_name)} ") as result:
rows = list(result)
column_list=[]
for k in range(0,len(result.schema.columns)):
get_column=str(result.schema.columns[k]).split("'")[1]
column_list.append(get_column.replace("'",""))
result=pd.DataFrame(rows)
result.columns=column_list
PATH_TO_DATA_CSV='/File_Path_Location/Tableau_Datasource_File_Name.csv'
result.to_csv(PATH_TO_DATA_CSV,index=False)
불러온 데이터를 수정한 뒤 다시 서버로 던져주기
이후 저장된 Dataframe을 사용하여 데이터 수정을 하고 다시 hyper로 변경 후 서버로 업데이트 방식을 사용하면 된다.
from tableauhyperapi import HyperProcess, Connection, TableDefinition, SqlType, Telemetry, Inserter, CreateMode, TableName
from tableauhyperapi import escape_string_literal
PATH_TO_HYPER ='/File_Path_Location/Tableau_Datasource_File_Name.hyper'
#CSV를 Hyper로 변환후 서버로 던질준비
with HyperProcess(Telemetry.SEND_USAGE_DATA_TO_TABLEAU, 'myapp' ) as hyper:
with Connection(endpoint=hyper.endpoint,
create_mode=CreateMode.CREATE_AND_REPLACE,
database=PATH_TO_HYPER) as connection:
connection.catalog.create_schema('Extract')
schema = TableDefinition(table_name=TableName('Extract','Extract'),
columns=[
TableDefinition.Column('컬럼명1', SqlType.text()),
TableDefinition.Column('컬럼명2', SqlType.date()),
TableDefinition.Column('컬럼명3', SqlType.text()),
TableDefinition.Column('컬럼명4', SqlType.int()),
TableDefinition.Column('컬럼명5', SqlType.double()),
])
connection.catalog.create_table(schema)
insert_csv_data = connection.execute_command(
command=f"COPY {schema.table_name} FROM {escape_string_literal(PATH_TO_CSV)} WITH "
f"(format csv,NULL 'NaN',delimiter ',', header)"
)
#데이터 원본을 저장할 프로젝트 ID를 검색
with server.auth.sign_in(tableau_auth):
all_project = list(TSC.Pager(server.projects, req_option))
project='Projects_Name'
project_id = [i.id for i in all_project if i.name==project]
project_name = [i.name for i in all_project if i.name==project]
print(project_id)
print(project_name)
#위의 데이터를 전송
try:
# Published Hyper to Tableau Server
conn = TableauServerConnection(config_json=TS_CONFIG, env='my_env')
conn.sign_in()
response= conn.publish_data_source(
datasource_file_path=PATH_TO_HYPER
,datasource_name='Datasource_Name'
,project_id='project_id')
conn.sign_out()
except:
pass
위의 빨간부분의 정보만 입력해주고 Pythond을 실행하면 아래 프로세스로 작동한다.
'Tableau 흡수내용' 카테고리의 다른 글
| [Tableau Driver]태블로 Spark SQL Driver Download 다운로드 (0) | 2022.11.28 |
|---|---|
| [Tableau(태블로)]이미지 필터링하기(다중 선택 가능) (0) | 2022.11.14 |
| [Tableau(태블로)]Fixed? 그게 뭔데? (0) | 2022.10.26 |
| [Tableau(태블로)]단계별 필터 표시하기 (0) | 2022.10.24 |
| [Tableau(태블로)]부분 카테고리 확장시키기 (0) | 2022.10.24 |



