빅데이터는 단순히 데이터의 크기(Volumn)이 크기만 한것이 아니라, 마치 나무의 뿌리처럼 이리 얽히고 저리 얽힌
수많은 데이터들의 집합이다.
그냥 관계형 DB처럼 데이터를 정리하게 되면 정규화로 인해 데이터의 안정성은 증가하지만,
데이터의 크기가 커지면 커질수록 테이블이 증가하게되고 불필요한 데이터들이 기하급수적으로 증가한다.
데이터가 커지면 당연하게도 연산 시간이 증가한다.
따라서 기존의 데이터 플랫폼으로는 빅데이터를 소화하기 어렵고, 빅데이터에 특화된 데이터 플랫폼이 필요하게 된것이다.
빅데이터를 사용할때 가장 필요한 사항은 아래와 같다.
1) 빅데이터 고속 추출
2) 실시간 스트리밍 데이터 수집
3) End To End 데이터 흐름을 트래킹할 수 있어야 합니다.
4) 플랫폼 사용유저의 보안
5) 검색 시스템
6) 대규모 사용자 트래픽 관리
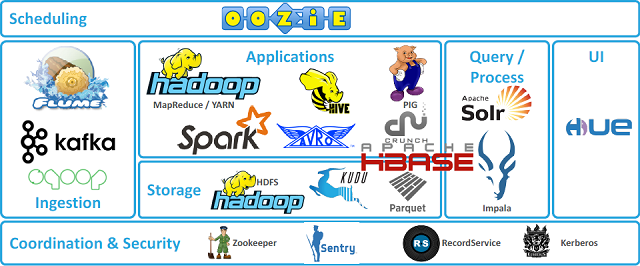
빅데이터 플랫폼 하면 무조건 따라나오는 단어가 있는데,
Hadoop 이라는 단어다.
Hadoop은 무엇인가, 빅데이터 분석 처리를 여러개의 컴퓨터로 진행함으로써 아주 큰 데이터도 병렬로 동시처리가 가능하게 해주는 솔루션이다.
그외에도 Yarn / Kafka / Spark / Hive / Impala같은 단어들을 들어봤을 것이다,
모두 기존에 이미 있었던 솔루션인데 빅데이터가 대두되면서 같이 급격하게 성장한 솔루션들이다.
위의 솔루션들을 사용하여 빅데이터 플랫폼을 구축할 경우 각 솔루션의 역할은 다음과 같다
1) 분산 코디네이터(ZooKeeper)
동기화 / 분산처리 및 분산 환경을 구성하는 서버 설정을 통합적으로 관리
2) 분산 리소스 관리(Yarn)
작업 스케쥴링 / 클러스터 리소스 관리를 위한 프레임워크이다,
맵 리듀스 / 하이브 / 임팔라 / 스파크 등 다양한 App들은 Yarn에서 작업을 실행합니다.
3) 데이터 저장(HDFS)
분산 파일 시스템 / HBase(분산 데이터 베이스) 구글 Bigtable을 기반으로 개발된 비관계형 DB이며,
Hadoop 및 HDFS위에 Bigtable과같은 기능을 제공한다.
4) 데이터 수집(Kafka)
데이터 스트리밍을실시간으로 관리하기 위한 분산 시스템 / 대용량 이벤트 처리를 위해 개발되었다.
5) 데이터 처리
Spark : 대규모 데이터처리를 위한 엔진
Impala : 임팔라는 하둡 기반 분석 엔진 / 맵리듀스가 아닌 C++를 사용한 인메모리 엔진
Hive : 하둡 기반 데이터 솔루션으로 오픈소스 / HiveQL이라는 SQL과 비슷한 언어를 사용하여
데이터 분석을 한다.
6) MapReduce
맵 리듀스는 빅데이터를 분산처리하기 위한 프로그램으로 정렬된 데이터를 Master 컴퓨터가
각각의 Slave컴퓨터들에게 분산처리(Map)하고 처리가 완료된 데이터를 다시 합치는과정(Reduce)을 진행한다.
'프로그래밍 > Spark&Hadoop 공부' 카테고리의 다른 글
| [Hadoop 설치하기]CentOS 7.9.2009(Linux)에서 Hadoop 2.7.7을 설치하는 과정들 (0) | 2022.11.24 |
|---|---|
| [Hadoop&Spark]Maven No goals have been Error (0) | 2022.11.23 |
| 1) 빅데이터란? (0) | 2022.06.29 |
| <%@page import="패키지명.클래스명" %> 500 error 에러 해결 -solved (0) | 2021.07.22 |
| [AWS / Spring / Tomcat]aws spring war파일 배포시 주의할점 / 에러 해결법 (0) | 2021.07.14 |

